
We have previously discussed Artificial Neural Networks (ANNs) and even gone through the details of Gradient Descent (Part-1 and Part-2 are available). Today it is time to dive more into the details of ANNs and study one of the most common activation functions ever invented, that is Relu.
Relu stands for Rectified Linear Unit and it is a popular activation function that is used in ANNs prevalently. It has certain advantages that its predecessors, Sigmoid (used during the early 1990s) and Tanh (used later in 1990s and through the 2000s), lack.
- For instance, both Sigmoid and Tanh suffer from the saturation problem as the gradient value near either of the extremes of these 2 functions approaches 0! This means that during training an ANN, while doing back-propagation, we will suffer from infinitesimal gradient values (effectively 0’s) and this means that training will slow down! This is called the vanishing gradient problem.
… sigmoidal units saturate across most of their domain—they saturate to a high value when z (i.e., their input) is very positive, saturate to a low value when z is very negative, and are only strongly sensitive to their input when z is near 0. — Page 195, Deep Learning, 2016
- As noted above, the other issue with both Sigmoid and Tanh is that they both are sensitive to changes only near their mid-point and as you go to either of the extremes of these 2 functions, their sensitivity lessens, which is where their gradient approaches 0. It is only near their mid-point that they have a nice non-linear behavior, but they approach a linear behavior as you go farther away from their mid-points.
Mathematically speaking, Relu(z) can be defined as follow:
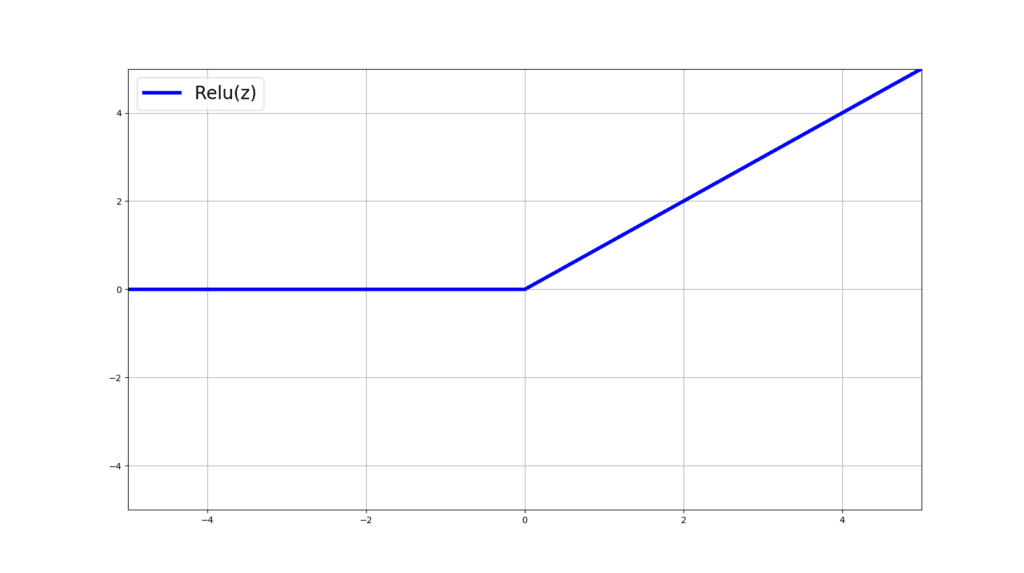
As you may have noticed, relu(z) is differentiable in all of its domain except when z=0. In other words, the left and right derivatives at z=0 exist BUT are not equal (i.e., at z=0, relu(z) is not differentiable). Then how is that it can be used in gradient-based learning methods such as in Artificial Neural Networks (ANNs)? During computing the gradients, what happens if we hit z=0? Would gradient descent and back-propagation simply fail?
The derivalive of relue(z) can be studied in 3 regions of its domin, namely, when z>0, z<0, and z=0. Let’s see the value of the gradients for the first two cases first:
This is easy to follow, right? Well, for all positive values of z, the slope of the tangent line is going to be 1. Similarly, for all z<0, this slope is 0. Now what about when z=0? Well relu(z) is not differentiable at z=0:
The left derivative of relu(z) w.r.t z is 0 and the right derivative is 1. However, since they are not equal, then relu(z) at z=0 does not exist! This effectively means that, the rate of change of relu(z) w.r.t z, at z=0, is different depending on whether you are getting infitely close to z=0 from its left side, or its right side (take a moment to absorbe this 😉 if that doesn’t make sense).
So, whet do we do? We do know that if we use relu(z) in training an ANN, we need to make sure that we can compute its derivative for all possible values of z! Here are a few ways to think about this problem:
- In an Artificial Neural Network (ANN), for a given neuron with relu(z) activation function, the chances of the pre-activation value z becoming exactly 0 is infinitesimally low!
- If by some unfortunate and unlikely disaster z becomes equal to exactly 0, then you might be tempted to just pass a random value as the gradient of relu(z) w.r.t z at z=0. Interestingly, since z=0 is a rare event, even with a random value for the gradient, the optimization process (e.g., gradeint descent) would get barely affected! It is like you update the parameters of your neural network towards a wrong direction once in a blue moon. Big deal!
- In certain platforms of deep learning such as Tensorflow, when z=0, the derivative of relu(z) w.r.t z is computed as 0. Their justification is that we should favour more sparce outputs for a better training experience.
- Some would choose the exact value of 0.5 as the gradient of relu(z) w.r.t z at z=0. Why? Well they argue that since the left and right gradients of relu(z) at z=0 are either 0 and 1, it makes sense to choose the mid-point 0.5 as the value of the gradient of relu(z) at z=0. This does not make much sense to me, personally!
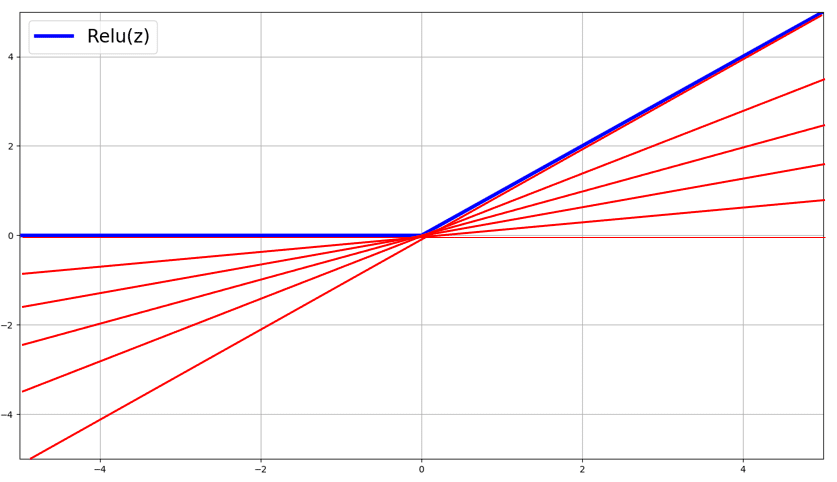
The slopes of these red lines, g, are the sub-gradients of relu(z) at z=0, where g is uniformly distributed! We know that for a given random variable g, with a certain probability distribution p(g) in the interval [a,b] the expectation is equal to:
And when g is uniformly distributed in the interval [a, b], p(g) must be:
So that the area under the curve would be exactly equal to 1. More specifically, this is a rectangular area, whose length is equal to and whose width is
. And clearly, the area of this rectangel is 1:
Otherwise, p(g) cannot be a probability distribution! In our case, the range [a,b] is equal to [0,1], as this is the range of possible values for the slopes of these sub-gradients.
Now, back to computing the expectation of these bloody sub-gradients (i.e., slopes of infite number of those red lines at z=0) represented by g:
From there let’s replace [a,b] with [0,1]:
So:
So, the expected value of the sub-gradient over infinitie number of sub-gradients is 0.5! I know! We ended up with the mid-point in the range [0,1]. However, I am more convinced by the “Expectation” arguement than I am with the “mid-point” arguement. So, this means that when z=0 (as rare as it is), define the candidate sub-gradient to be:
Moral of the story: You can choose any value in the range [0,1] and your ANN will still train. However, I like my expectation arguement as it lays a consistent arguement rather than just picking a random value!
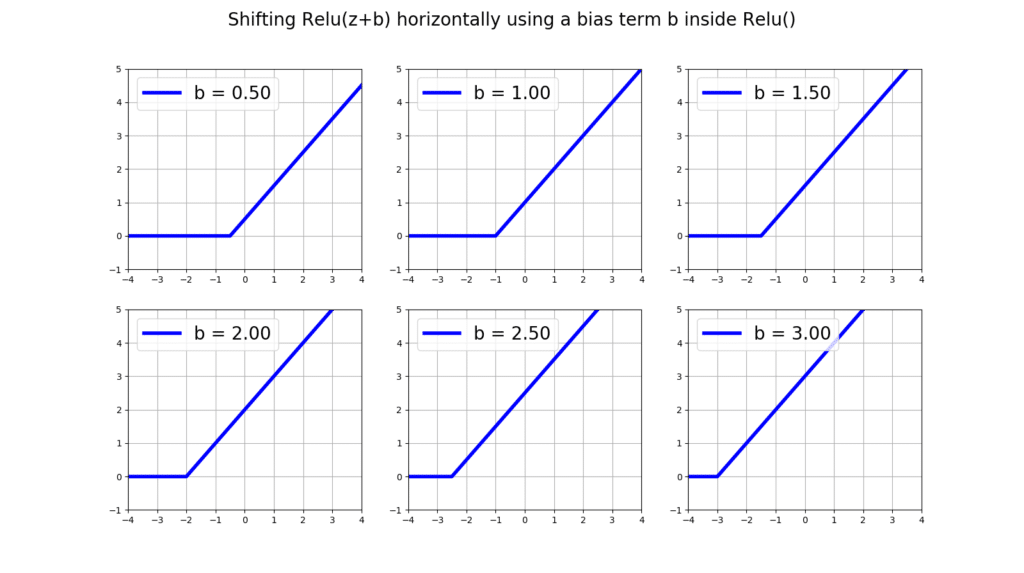
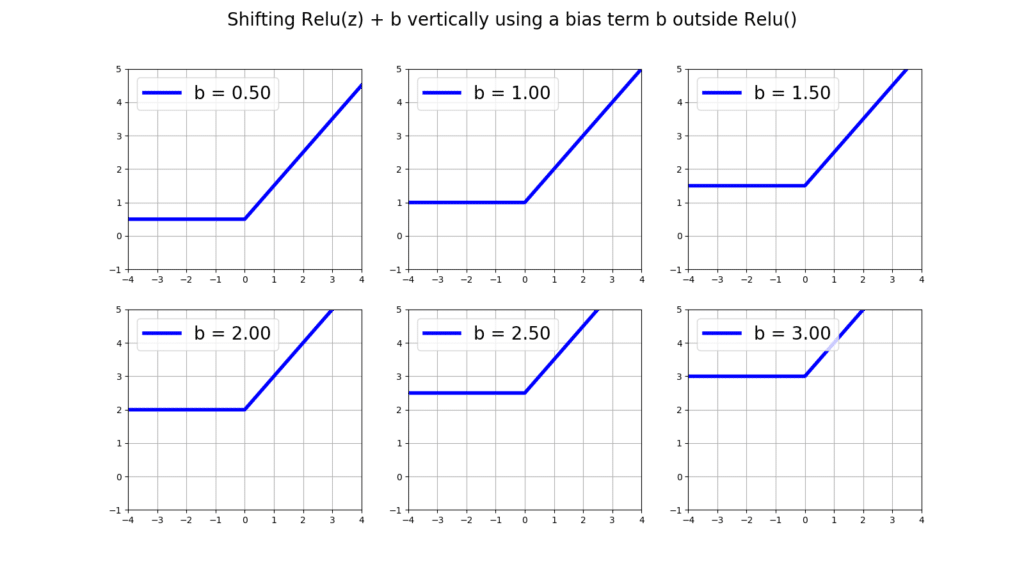
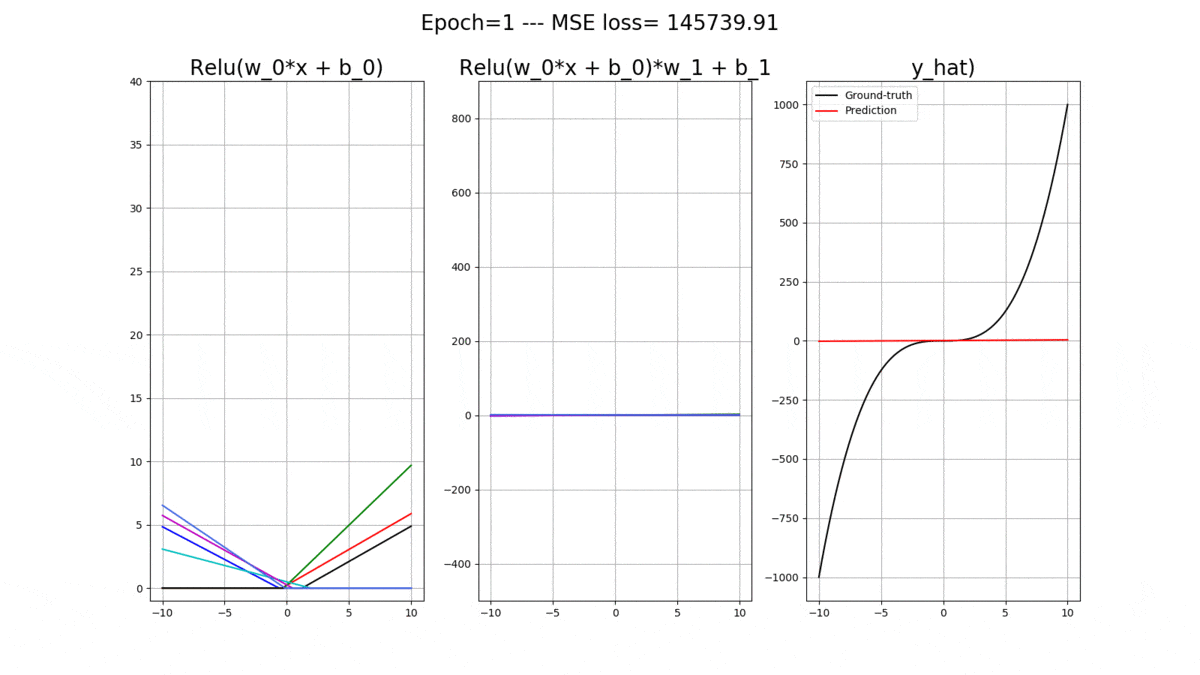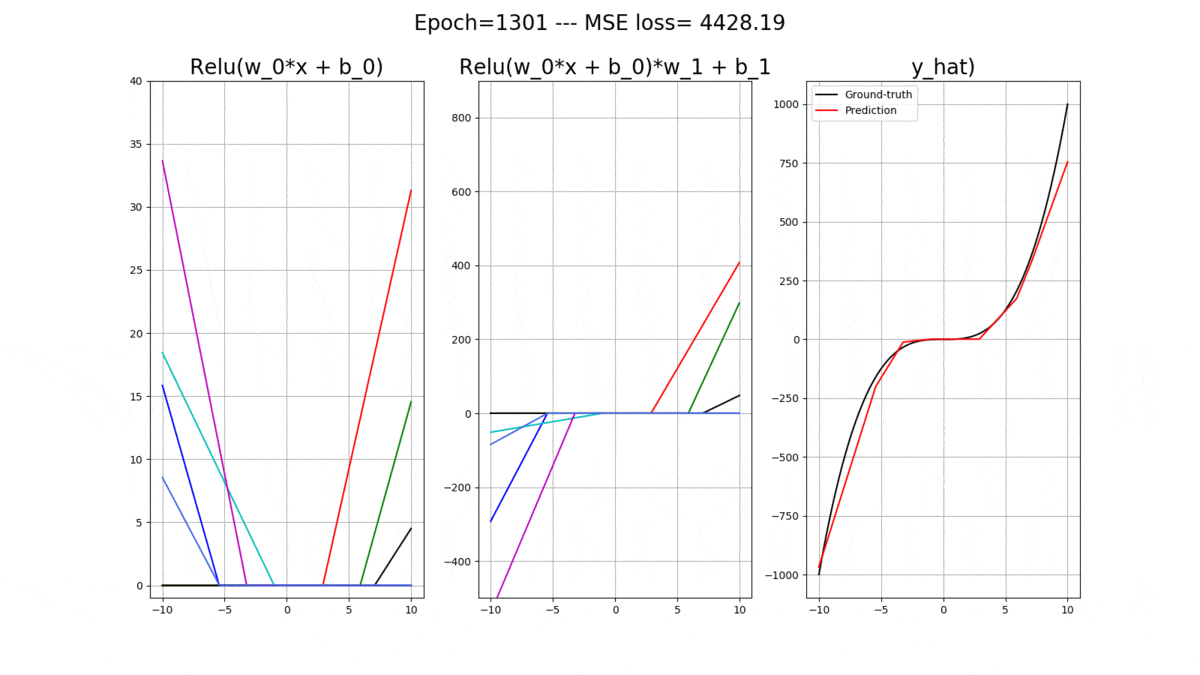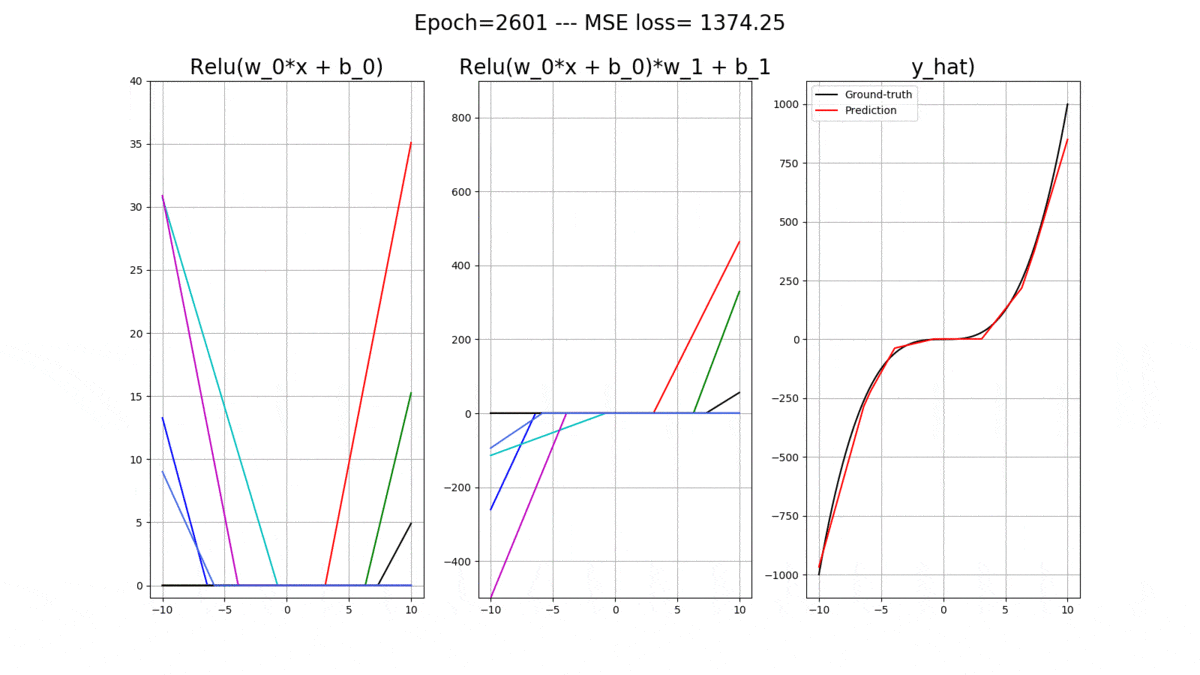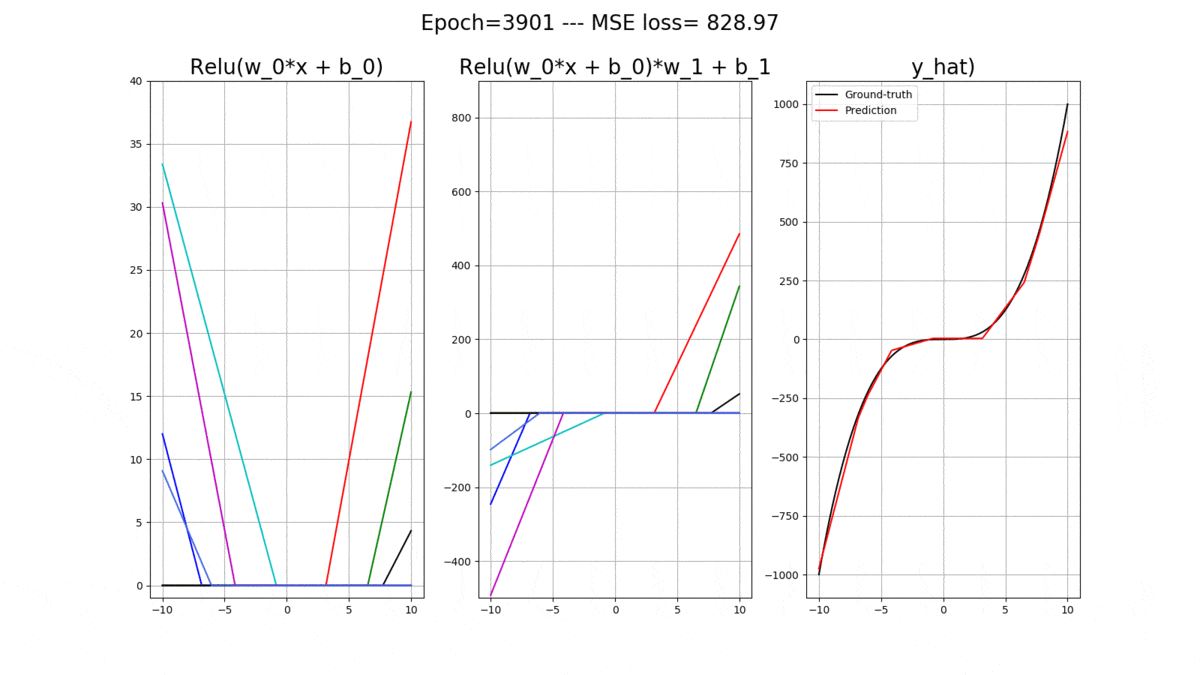
Let’s onsider a 1-layer ANN with 1 input and 1 output. Essentially, we will us it for the task of regression where given the input we will predict a real-valued output. The activation functions in the hidden layer are all relu(), and we have 2 bias units, one for the hidden layer and one for the output layer. Let’s denote all of the weights connecting the input data to the hidden layer with and all of the bias weights connecting to the hidden layer with
. Simiarly, let’s call all the weights conecting the hidden layer to the output node as
and the bias unit connectting to to the output node with
.
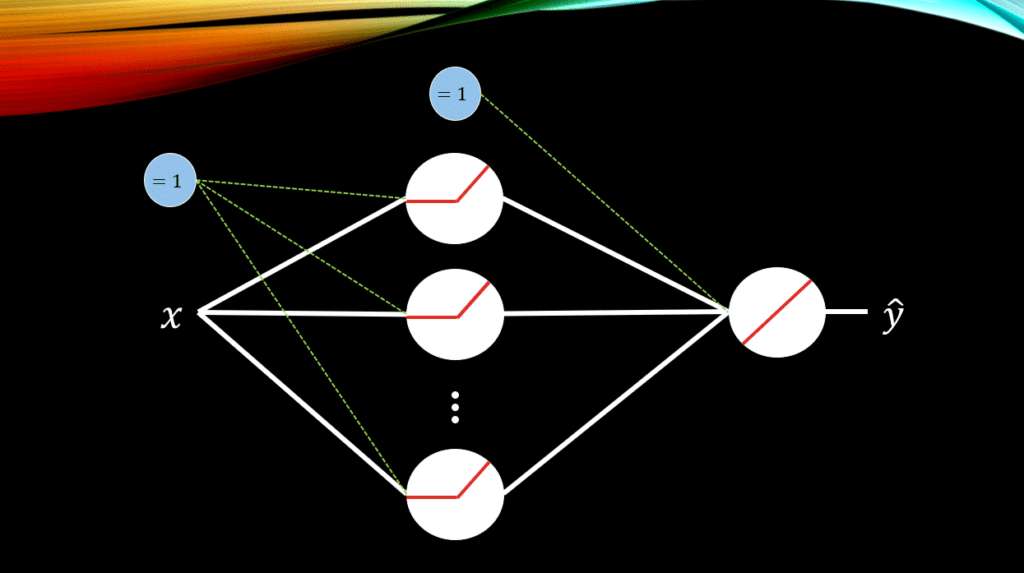
So, let’s get comfortable with the math. The activations at the hidden layer for each relu() is:
The final output of the model is then (Remember: The output neuron has a purely LINEAR activation function):
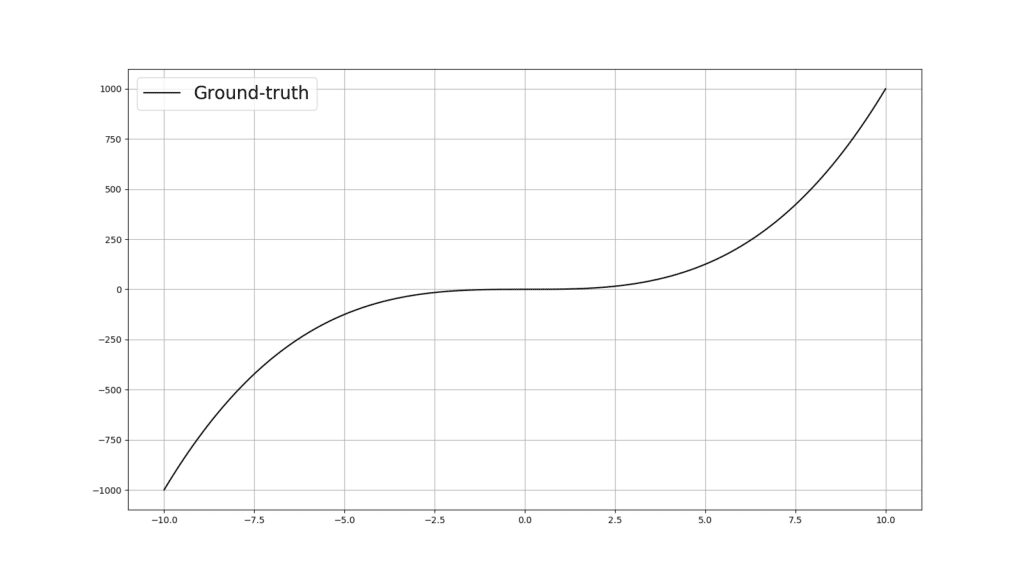
Now let’s code up a regressor using Pytorch, which can receive a desirable number of relu() neurons in its hidden layer, as an arguement. But first, let’s look at the curve that we would like the ANN learn to fit:
And then you realize it is a switch.
As per this blog post about 2 siding ReLU:
https://ai462qqq.blogspot.com/2023/03/2-siding-relu-via-forward-projections.html